
One of the key software qualities is reliability. And in order to build a reliable system, we need maturity, availability, recoverability and fault tolerance [1].
Fault tolerance refers to the ability of a system (computer, network, cloud cluster, etc.) to continue operating as per specifications even when one or more of its components encounter a fault [2].
In this article, we will review actionable failure metrics to measure fault tolerance.
The relationship between fault, error, failure and fault tolerance
When something happens that is outside of the spec expectations, we call it a fault. It can be a defect, a service taking longer than it should, a human-made error, power failure, etc. If the system goes into an invalid state which deviates from what was expected, then an error has occurred. The failure is defined as the system being unable to perform a function appropriately, or when there is no service at all.
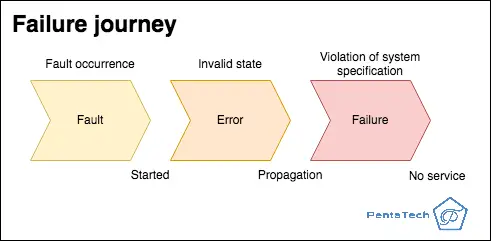
As a result, we call fault-tolerance the ability of a system to provide services even in the presence of faults, without going into invalid states.
Actionable failure metrics
Failure metrics are fundamental to manage outages that could negatively impact business. Apart from the following metrics, in other cases, business related metrics could be used to detect faults even if no failure has been detected. For instance, we can monitor number of orders, sales, visits, etc. and compare them again a benchmark for the same scenario; deviations could flag something is not right.
Let’s now review the failure metrics that are the cornerstone of reliability monitoring.
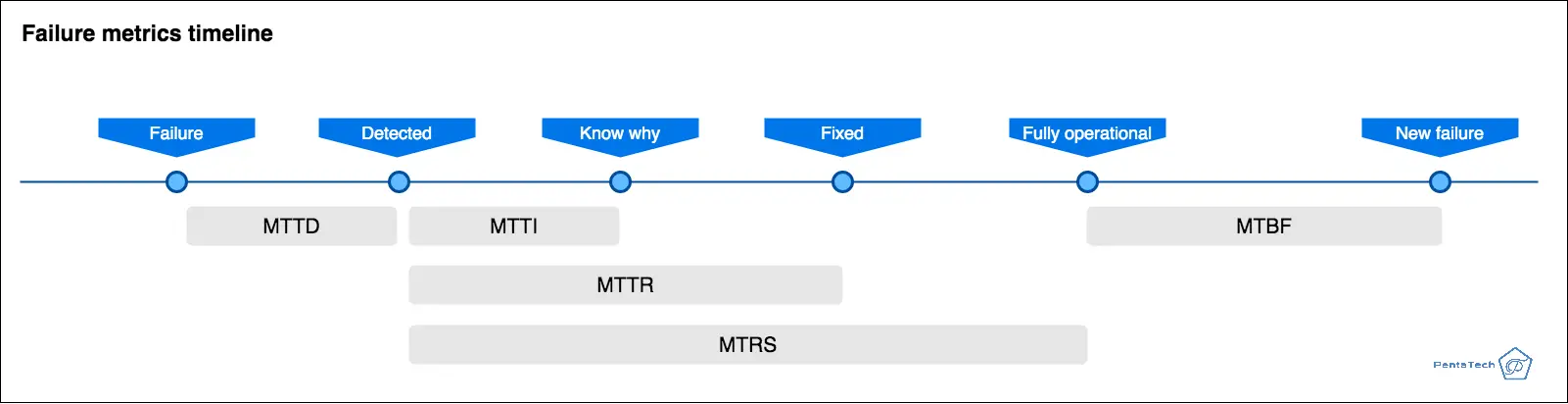
Mean Time to Detect (MTTD)
The average elapsed time between a failure and its detection. Once it is detected, then other metrics commence such as MTTI, MTTR and MTRS.
Mean Time to Failure (MTTF)
Mean time until a component fails. In other words, the average time a component or system is expected to function before it fails.
Mean Time to Repair (MTTR)
How long does it take to fix the system/component that failed? In other words, the average time between the failure of a system or component and when it is restored to full functionality [4].
Mean Time to Restore Service (MTRS)
The average time between detection and fully operational. The difference between MTTR and MTRS is that the later ensures the component/system is fully operational, meanwhile MTTR is only accounted until fixed.
Mean Time Between Failures (MTBF)
The average time between when the last failure was fixed and fully operational up until the next failure. In simple terms, for how long it was fully operational.
Failure rate
Out of all faults that took the system to an invalid state and left it not operational. In other words, the number of failures that have occurred during a period of time.



